Experimenting with GraphQL
Some background, a development team within the BGS Informatics department were tasked with creating an API to expose sensor data (in this case sensor data from instrumentation placed within boreholes). The API to be produced was to be a RESTful one, significant effort was expended iterating the API design, attempting to anticipate the needs of various user personas.
Sensor REST API: http://webservices.bgs.ac.uk/sensors/
OpenAPI: http://webservices.bgs.ac.uk/sensors/openapi
This is a BETA API service that will provide public access to BGS sensor data (seismic monitoring will be provided via a separate route), the BETA service includes metadata and data for the two environmental monitoring locations in Lancashire and Yorkshire as well as a geothermal monitoring observatory in Cardiff. It really is a beta service which is under active development, there are no restrictions on its use but availability or reliability are not guaranteed. Final caveat, the data is unchecked sensor data, it has not been cleaned up or adjusted to reflect maintenance events or other human influences on the data.
In an attempt to alleviate the need for predicting exactly which resources and payload structures a user would require, an evaluation of an alternative API type was undertaken - enter GraphQL. As a learning exercise a proof-of-concept was created using the Java implementation of GraphQL.
Introducing GraphQL?
What is GraphQL?
GraphQL is a data query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
Source: https://graphql.org/
GraphQL was initially created by Facebook to improve the network performance of their mobile applications, in 2015 the specification and JavaScript reference implementation were open sourced. Many popular programming languages (Java, Python, C#, Go) now support GraphQL, the community around GraphQL is growing with the creation of libraries and tools to support both client and server development.
Advantages
In no particular order:
- Increased Productivity: offers developers more freedom and speed to construct the queries they need without requiring modifications of the server code.
- Network Performance: because client applications can construct the exact query they require multiple network calls to multiple endpoints can be avoided - no over or under fetching of data.
- Unifying Systems: GraphQL supports the concept of integrating/combining multiple systems behind a single GraphQL API.
- Self Documenting: via introspection client applications can reconstruct the schema to determine exactly what queries and types are supported - documentation is always in sync with the implementation.
- Strong Typing: less error prone and more easily validated, earlier detection of bugs relating to the type of information sent in a query or received in a payload.
- Error Reporting: GraphQL implementations provide detailed error messages when there’s a problem processing queries or mutations, not relying solely on the HTTP status header to inform the client.
- Ecosystem: there is a growing ecosystem of developer tooling and libraries to GraphQL, building on its strong typing and introspection qualities.
Disadvantages
In no particular order:
- Web Caching: due to a GraphQL server typically only having one endpoint supporting multiple types of query it becomes a more complex problem to support caching. Several of the leading GraphQL client libraries have built in mechanisms to aid caching.
- File Uploading: uploading of files is not supported in the GraphQL specification, but there are several options to work around this: use a separate endpoint, encode the file contents in a mutation or use one of the client libraries that adds this functionality.
- Complex Queries: while enabling clients to create queries for exactly what they need, there can be issues if the client requests too many nested fields, or introduces circular references. These circumstances may warrant the development of fine tuned REST endpoints for specific complex queries.
- Learning Curve: There is a moderate learning curve, one to learn the GraphQL specification, and two learning the chosen client/server libraries.
A Simple Example
GraphQL services are created by defining the available operations (queries “read” and mutations “write”), object types, their fields (fields can have arguments - much like functions or methods in other languages) and their relationships using the GraphQL type system and language - these form a GraphQL schema that is then exposed to clients and implemented server-side.
- Operation: A query, or mutation to be interpreted.
- Query: A read-only fetch operation to request data.
- Mutation: An operation for creating, modifying and destroying data.
- Type: An (object) type in a GraphQL schema that has fields.
- Field: A unit of data, that will correspond to a field in the JSON response.
The schema allows client developers to see exactly what data is available and how to construct optimised queries and mutation requests.
Books and Authors
The schema below presents the concept of books and authors, a book has an author and title, an author has a name and may have authored a number of books.
Schema: Object Types
type Book {
title: String
author: Author
}
type Author {
name: String
books: [Book]
}
The Query type defines the root queries a client can make against a GraphQL API, it resembles an object type - but is always called Query.
Query Type
type Query {
getBooks: [Book]
getAuthors: [Author]
}
Using the simple schema defined above a client query to receive a list of book titles would be.
Query
query {
getBooks {
title
}
}
Response Payload (JSON)
{
"data": {
"getBooks": [
{
"title": "Clean Code"
},
...
]
}
}
If the client decided they also wanted the name of author, it would simply be a case of modifying the query, there is no need to change the underlying implementation to update the payload structure.
Updated Query
query {
getBooks {
title
author {
name
}
}
}
Updated Response Payload (JSON)
{
"data": {
"getBooks": [
{
"title": "Clean Code",
"author": {
"name": "Robert C. Martin"
}
},
...
]
}
}
Learn more at: https://graphql.org/learn/
Proof of Concept: Sensor API
The proof-of-concept used the Java implementation ( https://github.com/graphql-java/graphql-java) of the GraphQL specification to implement the API, a micro-web-framework ( https://javalin.io/ ) was chosen to serve the GraphQL API to allow development to concentrate on the GraphQL aspect, along with test frameworks ( https://junit.org/junit5/ and http://rest-assured.io/ ) to verify functionality.
Sensor API Schema
Below is a small section of the draft GraphQL Sensor API schema.
type Query{
sites : [Site!]!
siteBySiteCode(siteCode: String!) : Site
...
}
type Site{
name : String!
description : String!
code : String!
nodes : [Node!]!
}
type Node{
name : String!
code : String!
sensors : [Sensor!]!
}
type Sensor{
name : String!
code : String!
location: Location!
...
}
Sensor API Queries
Below are illustrative queries supported by the GraphQL Sensor API and sample response payloads.
Query for all sites.
query {
sites {
name
description
code
}
}
Response payload for all sites (JSON).
{
"data": {
"sites": [
{
"name": "Lancashire Monitoring",
"description": "Lancashire Monitoring",
"code": "10"
},
{
"name": "BGS Cardiff",
"description": "BGS Cardiff",
"code": "11"
},
{
"name": "Yorkshire Monitoring",
"description": "Yorkshire Monitoring",
"code": "12"
}
]
}
}
Query for all types of phenomena being monitored.
query {
phenomena {
name
code
}
}
Response payload for all types of phenomena being monitored (JSON).
{
"data": {
"phenomena": [
{
"name": "Soil Salinity 40cm",
"code": "96",
"description": "unavailable"
},
{
"name": "Soil Temperature 15cm",
"code": "104",
"description": "unavailable"
},
{
"name": "Soil Moisture 30cm",
"code": "92",
"description": "unavailable"
},
...
]
}
}
Sensor API (Java) Implementation
As with many an API, a suitable data model was developed to represent the domain objects to be exposed, along with a data-access layer that would allow different data-sources to be switched in/out - in this case a database containing real sensor readings, or a mock data-source for testing purposes.
A few of the entities in the data model
public interface Entity {
String name();
String code();
}
public interface Site extends Entity, Described {
...
}
public interface Sensor extends Entity {
Location location();
...
}
A snippet of the data access layer
public interface DataAccess {
Set<Site> getSites();
Set<Node> getNodes();
Set<Node> getNodesBySite(String siteCode);
Set<Sensor> getSensors();
Set<Sensor> getSensorsBySite(String siteCode);
Set<Sensor> getSensorsByNode(String nodeCode);
...
Common code for gluing together the web-framework, data-access and GraphQL implementation was created to handle incoming web-requests, passing valid requests onto the implementation of the GraphQL sensor schema, which would then access the data-source to build the JSON payloads to respond with.
The interesting piece of the puzzle was to evaluate how easy/difficult it would be to ‘wire up’ the GraphQL implementation of the sensor schema, as mentioned above the https://github.com/graphql-java/graphql-java library was used to provide the core GraphQL functionality, the ‘wiring up’ of over 15 root queries and over 15 distinct types was achieved in less than 900 lines of code.
The act of ‘wiring up’ a GraphQL API is completed through the creation of TypeResolvers and DataFetchers for the various types and fields defined in a schema. TypeResolvers are used to determine the concrete type of objects that are being referenced via a GraphQL interface (GraphQL has interfaces in its type system much like Java does), whereas DataFetchers do pretty much what you’d expect - they know how to access the data for the fields defined on GraphQL types.
Building a Data-fetcher for the ‘sites’ query on the Query type
// Query type
builder.type(QUERY_TYPE, b -> {
//Support for the sites query
b.dataFetcher(SITES_FIELD, new DataFetcher<List<Site>>() {
@Override
public List<Site> get(final DataFetchingEnvironment e) throws Exception {
final Set<Site> sites = dataAccess.getSites();
return mapToList(sites, s -> s);
}
});
...
Building a data-fetcher for the sensors field on the Node type
// Node type
builder.type(NODE_TYPE, b -> {
//Support for scalar values (name, description etc.)
setDefaultDataFetcherToSupportMethodNames(b);
//Support for a Node to returns it's list of Sensor(s)
b.dataFetcher(SENSORS_FIELD, new DataFetcher<List<Sensor>>() {
@Override
public List<Sensor> get(final DataFetchingEnvironment e) throws Exception {
final Object source = e.getSource();
return PatternMatching.<List<Sensor>>match(source).//
whenType(Node.class, node -> mapToList(dataAccess.getSensorsByNode(node.code()), s -> s)).//
otherwise().orElse(List.of());
}
});
return b;
});
...
During development, in the absence of a true client application, the GraphQL Playground IDE ( https://github.com/prisma-labs/graphql-playground ) was used to construct & test queries, view response payloads (or errors), and reconstruct the schema as seen by clients via introspection - note support for introspection queries is built into the core GraphQL libraries used to implement the API.
GraphQL Playground
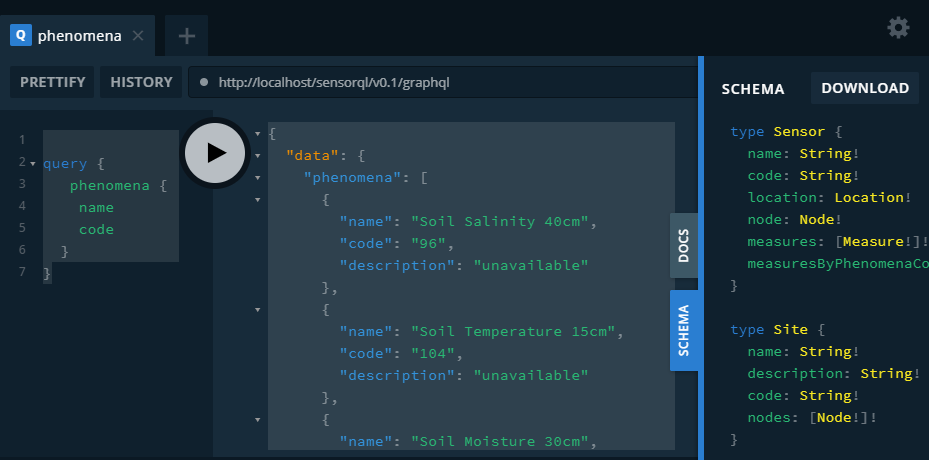
Left: query string. Middle: response payload. Right: schema through introspection.
Summary
Use Cases
GraphQL represents a viable alternative to REST, but not necessarily a replacement. As with many aspects of software development there will be trade-offs to make, requiring an evaluation of GraphQL’s suitability.
The scenarios under which GraphQL would appear suited are:
- Flexibility: where client development requires the flexibility to update queries and requested payloads without needing the ability to modify the API implementation.
- Uncertainty: where there is uncertainty around which queries and payload structures are required.
- Network Performance: where reducing the amount of data transferred is paramount, i.e. mobile app development.
- Unification: presenting a unified (or gateway) API onto a micro-service architecture, external clients only need interact with one ‘unified’ API, with the details of individual micro-services remaining hidden.
GraphQL maybe less relevant where there are existing standards for exposing a specific type of data.
Implementation
There is a moderate learning curve to adopting GraphQL, firstly to learn the specification (new topics and concepts can be introduced as required though), secondly to learn the libraries and tooling needed to implement the API and/or clients. Once the basics were understood, development of the sensor proof-of-concept was relatively swift. As with any kind of API development, it’s the definition of a good schema/specification that will make or break the success of an API - so it’s worth investing time in this activity.
Additional Information
-
GraphQL: https://graphql.org/
-
GraphQL Learn: https://graphql.org/learn/
-
GraphQL Foundation: https://foundation.graphql.org/
-
Awesome GraphQL: https://github.com/chentsulin/awesome-graphql
-
GraphQL Java: https://github.com/graphql-java/graphql-java
-
GraphQL Playground: https://github.com/prisma-labs/graphql-playground
-
GraphQL Clients
comments